従来、私の認識ではHDD中の不良領域を使用しないようにしたものがスキップセクタであるという程度の理解をしていました。
そこから一歩踏み込んで、スキップセクタを管理しているのはファイルシステム(OS)なのか、HDD自体(のファームウェア)なのかについて、明確に答えられる人はどれほどいるでしょうか?少なくとも、私は知りませんでした。
この辺を説明している記事もほとんど見かけませんので、今回調べたことを記載しておきます。
はじめに
シングルボードコンピュータで自作したLinux NASで使用していたUSB接続の外付けHDDに障害が発生し、一部のファイルが正常にR/Wできなくなりました。当該HDDに既に記録済の読み出し可能なデータは別のHDDにコピーし、問題のHDDは取り外しました。
このHDDを再使用するか廃棄するかを決めるため状態確認を始めたのが、今回の調査のきっかけです。
試行した事をシーケンシャルに記載していますので、読み物としては読み難いかもしれませんが、ご了承ください(結論にだけ興味があれば、末尾のまとめまで読み飛ばしてください)。
問題検知
NASへのファイルコピーに失敗し、NASのdmesgを確認すると約5分おきに以下のようなエラーが同一logical blockについて出力されていました。
[Timestamp] sd 3:0:0:0: [sdc] tag#0 UNKNOWN(0x2003) Result: hostbyte=0x00 driverbyte=0x08 [Timestamp] sd 3:0:0:0: [sdc] tag#0 Sense Key : 0x3 [current] [Timestamp] sd 3:0:0:0: [sdc] tag#0 ASC=0x11 ASCQ=0x0 [Timestamp] sd 3:0:0:0: [sdc] tag#0 CDB: opcode=0x28 28 00 00 00 1e b0 00 00 08 00 [Timestamp] print_req_error: critical medium error, dev sdc, sector 7856 [Timestamp] Buffer I/O error on dev sdc, logical block 982, async page read
このHDDはNTFSでフォーマットされたもので、空き容量も十分にある状態でした。
Filesystem Type Size Used Avail Use% Mounted on /dev/sdc fuseblk 1.9T 1.4T 451G 76% /srv/dev-disk-by-label-******
SMART情報を確認してみると、温度について警告されているのが一見して判ります。
SMART Attributes Data Structure revision number: 10 Vendor Specific SMART Attributes with Thresholds: ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE 1 Raw_Read_Error_Rate 0x000f 098 098 006 Pre-fail Always - 144724101 3 Spin_Up_Time 0x0003 095 095 000 Pre-fail Always - 0 4 Start_Stop_Count 0x0032 100 100 020 Old_age Always - 232 5 Reallocated_Sector_Ct 0x0033 100 100 010 Pre-fail Always - 0 7 Seek_Error_Rate 0x000f 057 057 030 Pre-fail Always - 34363578684 9 Power_On_Hours 0x0032 077 077 000 Old_age Always - 20648 10 Spin_Retry_Count 0x0013 100 100 097 Pre-fail Always - 0 12 Power_Cycle_Count 0x0032 100 100 020 Old_age Always - 216 183 Runtime_Bad_Block 0x0032 100 100 000 Old_age Always - 0 184 End-to-End_Error 0x0032 100 100 099 Old_age Always - 0 187 Reported_Uncorrect 0x0032 015 015 000 Old_age Always - 85 188 Command_Timeout 0x0032 100 099 000 Old_age Always - 1 1 1 189 High_Fly_Writes 0x003a 100 100 000 Old_age Always - 0 190 Airflow_Temperature_Cel 0x0022 042 040 045 Old_age Always FAILING_NOW 58 (Min/Max 23/60 #9362) 191 G-Sense_Error_Rate 0x0032 100 100 000 Old_age Always - 0 192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 13 193 Load_Cycle_Count 0x0032 097 097 000 Old_age Always - 7184 194 Temperature_Celsius 0x0022 058 060 000 Old_age Always - 58 (0 6 0 0 0) 197 Current_Pending_Sector 0x0012 100 100 000 Old_age Always - 72 198 Offline_Uncorrectable 0x0010 100 100 000 Old_age Offline - 72 199 UDMA_CRC_Error_Count 0x003e 200 200 000 Old_age Always - 0 240 Head_Flying_Hours 0x0000 100 253 000 Old_age Offline - 6019h+01m+45.865s 241 Total_LBAs_Written 0x0000 100 253 000 Old_age Offline - 10857645464 242 Total_LBAs_Read 0x0000 100 253 000 Old_age Offline - 51520974114
他にも、以下のようにSMARTが記録しているエラーが85回発生していることが判ります。また、直近5回のエラー(と、その直前に実行された5回のコマンド)時のレジスタ情報については詳細にログに記録されていました。
SMART Error Log Version: 1 ATA Error Count: 85 (device log contains only the most recent five errors) CR = Command Register [HEX] FR = Features Register [HEX] SC = Sector Count Register [HEX] SN = Sector Number Register [HEX] CL = Cylinder Low Register [HEX] CH = Cylinder High Register [HEX] DH = Device/Head Register [HEX] DC = Device Command Register [HEX] ER = Error register [HEX] ST = Status register [HEX] Powered_Up_Time is measured from power on, and printed as DDd+hh:mm:SS.sss where DD=days, hh=hours, mm=minutes, SS=sec, and sss=millisec. It "wraps" after 49.710 days. Error 85 occurred at disk power-on lifetime: 20644 hours (860 days + 4 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 51 00 6f 01 00 00 Error: UNC at LBA = 0x0000016f = 367 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 00 01 6f 01 00 40 00 8d+19:30:44.375 READ DMA EXT 25 00 01 6e 01 00 40 00 8d+19:30:40.257 READ DMA EXT 25 00 01 6d 01 00 40 00 8d+19:30:36.399 READ DMA EXT 25 00 01 6c 01 00 40 00 8d+19:30:32.464 READ DMA EXT 25 00 01 6b 01 00 40 00 8d+19:30:28.405 READ DMA EXT Error 84 occurred at disk power-on lifetime: 20644 hours (860 days + 4 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 51 00 6e 01 00 00 Error: UNC at LBA = 0x0000016e = 366 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 00 01 6e 01 00 40 00 8d+19:30:40.257 READ DMA EXT 25 00 01 6d 01 00 40 00 8d+19:30:36.399 READ DMA EXT 25 00 01 6c 01 00 40 00 8d+19:30:32.464 READ DMA EXT 25 00 01 6b 01 00 40 00 8d+19:30:28.405 READ DMA EXT 25 00 01 6a 01 00 40 00 8d+19:30:24.405 READ DMA EXT Error 83 occurred at disk power-on lifetime: 20644 hours (860 days + 4 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 51 00 6d 01 00 00 Error: UNC at LBA = 0x0000016d = 365 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 00 01 6d 01 00 40 00 8d+19:30:36.399 READ DMA EXT 25 00 01 6c 01 00 40 00 8d+19:30:32.464 READ DMA EXT 25 00 01 6b 01 00 40 00 8d+19:30:28.405 READ DMA EXT 25 00 01 6a 01 00 40 00 8d+19:30:24.405 READ DMA EXT 25 00 01 69 01 00 40 00 8d+19:30:20.187 READ DMA EXT Error 82 occurred at disk power-on lifetime: 20644 hours (860 days + 4 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 51 00 6c 01 00 00 Error: UNC at LBA = 0x0000016c = 364 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 00 01 6c 01 00 40 00 8d+19:30:32.464 READ DMA EXT 25 00 01 6b 01 00 40 00 8d+19:30:28.405 READ DMA EXT 25 00 01 6a 01 00 40 00 8d+19:30:24.405 READ DMA EXT 25 00 01 69 01 00 40 00 8d+19:30:20.187 READ DMA EXT 25 00 01 68 01 00 40 00 8d+19:30:16.183 READ DMA EXT Error 81 occurred at disk power-on lifetime: 20644 hours (860 days + 4 hours) When the command that caused the error occurred, the device was active or idle. After command completion occurred, registers were: ER ST SC SN CL CH DH -- -- -- -- -- -- -- 40 51 00 6b 01 00 00 Error: UNC at LBA = 0x0000016b = 363 Commands leading to the command that caused the error were: CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name -- -- -- -- -- -- -- -- ---------------- -------------------- 25 00 01 6b 01 00 40 00 8d+19:30:28.405 READ DMA EXT 25 00 01 6a 01 00 40 00 8d+19:30:24.405 READ DMA EXT 25 00 01 69 01 00 40 00 8d+19:30:20.187 READ DMA EXT 25 00 01 68 01 00 40 00 8d+19:30:16.183 READ DMA EXT 25 00 01 08 00 00 40 00 8d+19:30:16.111 READ DMA EXT
このログから直近5回のエラーはLBA=363~367と連続した領域で発生したことが判ります。
ただしLBAはLogical Block Addressの名の通り論理的なアドレスであり、物理的なアドレス(PBA; Physical Block Address)ではありません。すなわち、物理的にプラッタ表面の同一トラック上の隣り合ったセクタで問題が発生したのかは断定できません。
初期対応
- NASに新規HDD追加
- 障害発生HDD上の読み出し可能なデータを、新規に追加した別のHDDにコピー
- 欠落したファイル(読み出せなかったファイル)の特定
- 障害発生HDDを取り外し
実はこのまま1年以上放置していたのです*1。
最近になって、高い信頼性は要求しないものの、まとまった記憶容量が必要になったので、このHDDがまだ使えそうか調査することにしました。
状況調査
Linuxで簡易確認
とりあえずLinuxマシンに繋いでみました。syslogを確認するとusb-storageなハードウェアとしては正常に認識されます。
kernel: [ 1.875915] usb 2-2: new SuperSpeed Gen 1 USB device number 2 using xhci_hcd kernel: [ 1.897144] usb 2-2: New USB device found, idVendor=0bc2, idProduct=3322, bcdDevice= 1.00 kernel: [ 1.897147] usb 2-2: New USB device strings: Mfr=2, Product=3, SerialNumber=1 kernel: [ 1.897148] usb 2-2: Product: Expansion Desk kernel: [ 1.897149] usb 2-2: Manufacturer: Seagate kernel: [ 1.897150] usb 2-2: SerialNumber: **************** kernel: [ 1.903179] usbcore: registered new interface driver usb-storage kernel: [ 1.907119] scsi host3: uas
が、以下のようなエラーが出力されており、logical block 128~135が読み出せないと言っています。
kernel: [ 3.620131] blk_update_request: I/O error, dev sda, sector 128 op 0x0:(READ) flags 0x80700 phys_seg 48 prio class 0 kernel: [ 3.620196] blk_update_request: I/O error, dev sda, sector 128 op 0x0:(READ) flags 0x0 phys_seg 8 prio class 0 kernel: [ 3.620200] Buffer I/O error on dev sda, logical block 128, async page read kernel: [ 3.620202] Buffer I/O error on dev sda, logical block 129, async page read kernel: [ 3.620203] Buffer I/O error on dev sda, logical block 130, async page read kernel: [ 3.620205] Buffer I/O error on dev sda, logical block 131, async page read kernel: [ 3.620206] Buffer I/O error on dev sda, logical block 132, async page read kernel: [ 3.620208] Buffer I/O error on dev sda, logical block 133, async page read kernel: [ 3.620209] Buffer I/O error on dev sda, logical block 134, async page read kernel: [ 3.620210] Buffer I/O error on dev sda, logical block 135, async page read kernel: [ 3.620273] blk_update_request: I/O error, dev sda, sector 128 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 kernel: [ 3.620275] Buffer I/O error on dev sda, logical block 128, async page read kernel: [ 3.620295] blk_update_request: I/O error, dev sda, sector 129 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 kernel: [ 3.620297] Buffer I/O error on dev sda, logical block 129, async page read kernel: [ 3.620304] blk_update_request: I/O error, dev sda, sector 130 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 kernel: [ 3.620311] blk_update_request: I/O error, dev sda, sector 131 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 kernel: [ 3.620318] blk_update_request: I/O error, dev sda, sector 132 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 kernel: [ 3.620324] blk_update_request: I/O error, dev sda, sector 133 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 kernel: [ 3.620330] blk_update_request: I/O error, dev sda, sector 134 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 kernel: [ 3.620336] blk_update_request: I/O error, dev sda, sector 135 op 0x0:(READ) flags 0x0 phys_seg 1 prio class 0 kernel: [ 3.621168] sd 3:0:0:0: [sda] Synchronizing SCSI cache kernel: [ 3.860009] sd 3:0:0:0: [sda] Synchronize Cache(10) failed: Result: hostbyte=DID_ERROR driverbyte=DRIVER_OK
出力されているlogical blockの番号がだいぶ若いですから、パーティションテーブルやスーパーブロック相当の領域が損傷しているのかもしれません。実際にマウントできない状況になっています。
なお、このsyslog中のlogical blockの番号がLBAそのものなのかは判りませんが、かつてNASで確認したLBA=363~367とは異なってますから、恐らく複数の論理的に連続した領域が損傷していると考えられます。
Windowsで確認
このHDDで使用していたファイルシステムはNTFSなのですが、Windows PCに繋いでもHDDの存在は認識されるもののマウントされません。
CrystalDiskInfoでSMART情報を確認すると、"Current Pending Sector Count", "Uncorrectable Sector Count"の2項目の値が0x38すなわち56個のセクタで問題が発生しており、これについて警告表示されています。

かつてNAS上でsmartctlで確認した値は72(すなわち0x48)でしたが、何故か減っています。
いずれにせよ保留中のセクタや修復不能セクタが存在することは間違いないのでしょう。
SeaToolsで修復
当該HDDはSeagate製ですので、Seagate純正ツールSeaToolsを使って検査・修復を試みることにしました。
手始めに、ショートセルフテストを実行したところ、以下のように「失敗」表示となりました。
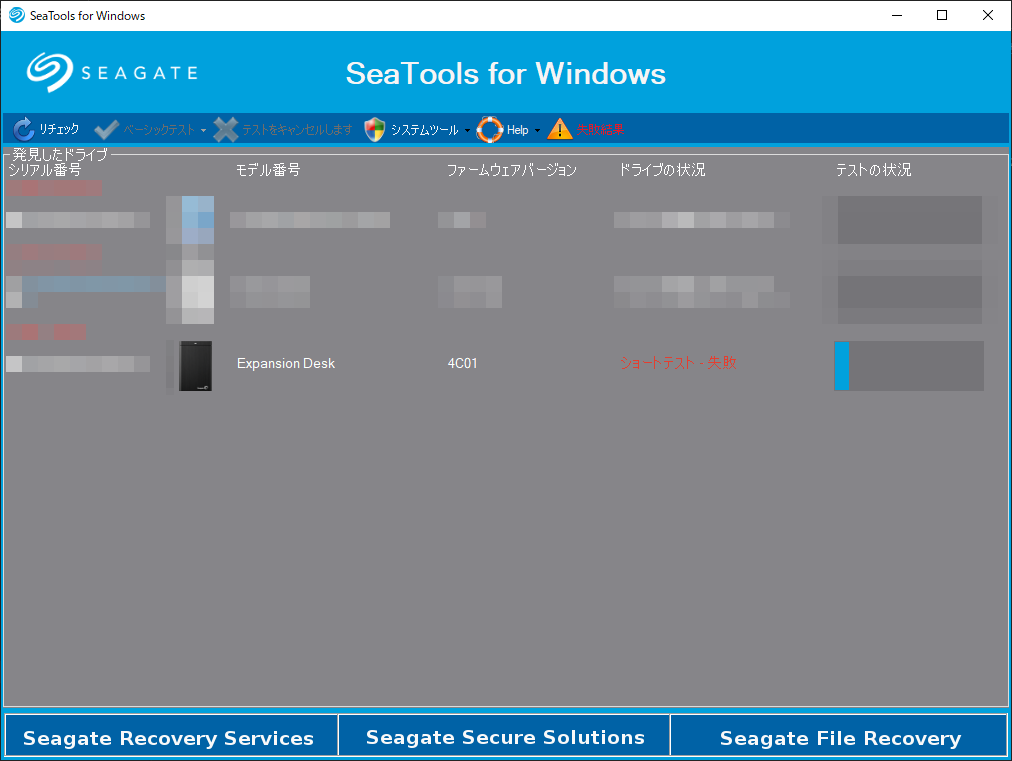
詳細を確認するとセクタに異常がある旨表示されています。

この時のログは以下の通りでした。
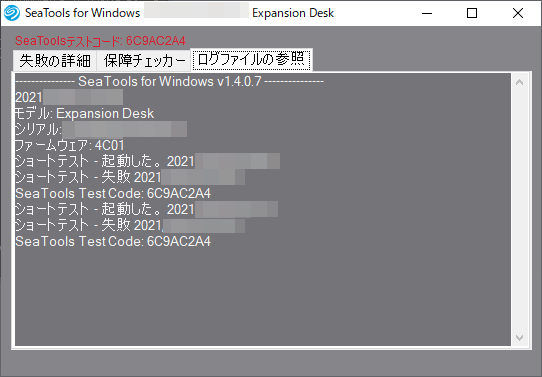
続いて、修復を試みることにします。SeaToolsでは「高速修復」と「ロング修復」の2種類の修復方法が選択可能です。
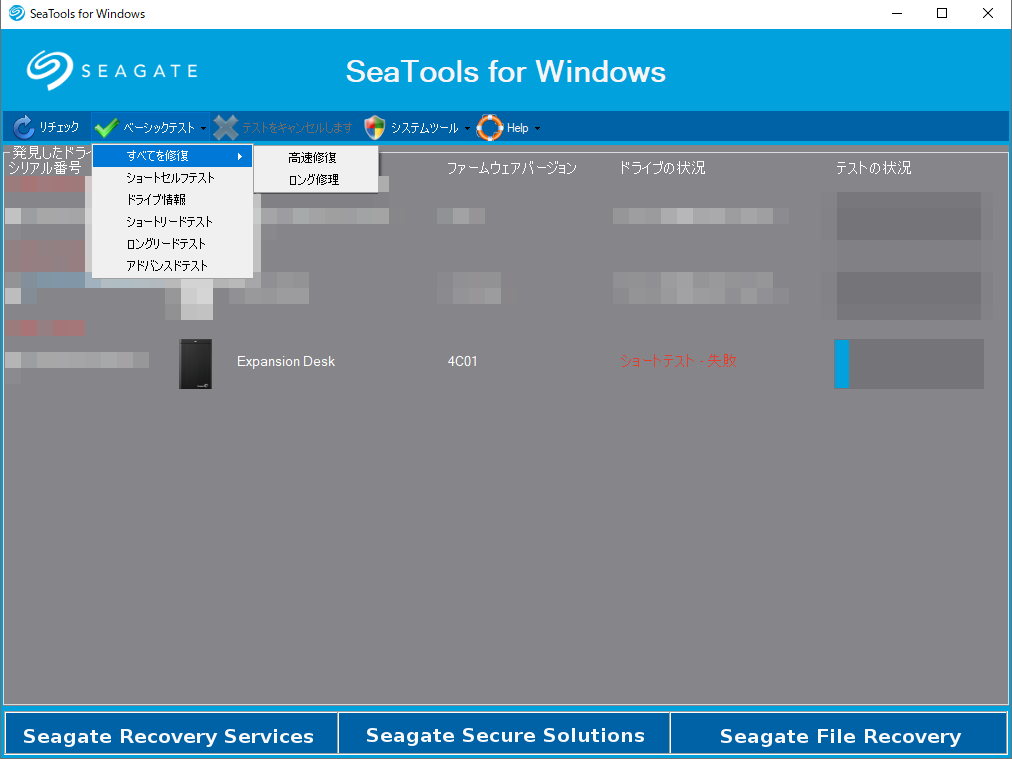
高速修復が失敗したらロング修復を試してみればいいかなという考えで、高速修復を選択しました。すると以下のようにデータ損失の責任は負わない旨、警告が表示されます。
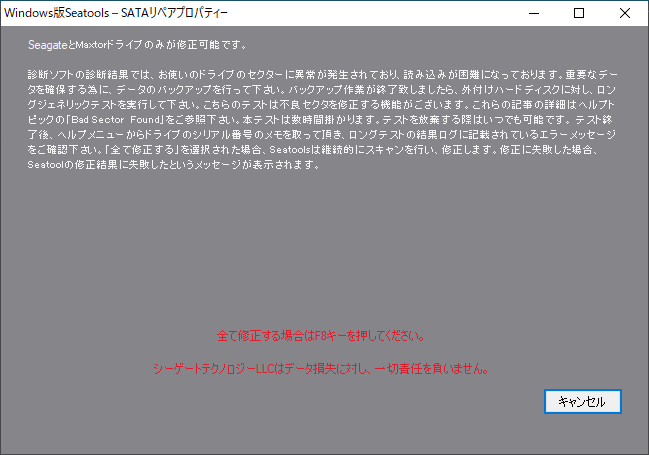
F8キーを押して高速修復を実行したところ、ごく短時間(体感で1分程度)で修復が完了し、「成功」表示となりました。
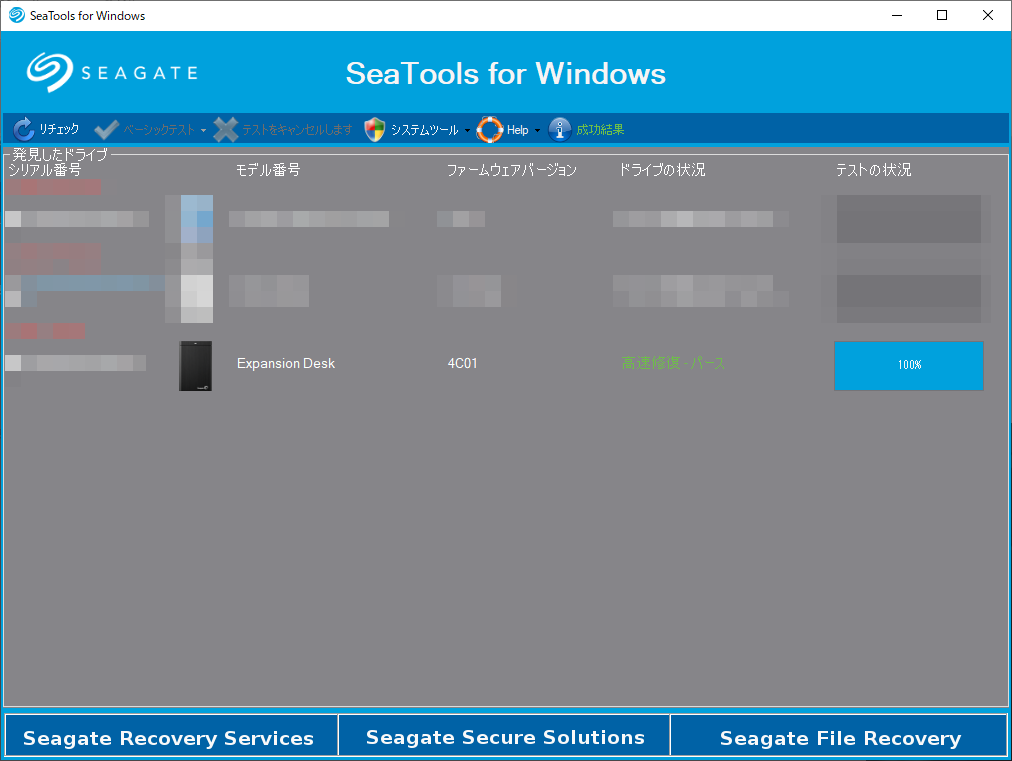
詳細を確認すると、高速修復前に表示されていたセクタ異常は表示されなくなっています。

この時のログは以下の通りでした。
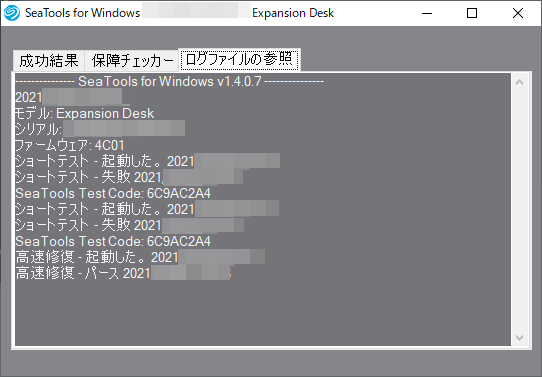
改めて、ショートセルフテストを実行すると「成功」表示となりますが、何がどう修復されたのか解る情報は特に表示されません。
Windowsで再確認
USBポートを再接続しなおしても、相変わらずWindowsはHDDをマウントしてくれません。
CrystalDiskInfoでSMART情報を確認すると、"Current Pending Sector Count", "Uncorrectable Sector Count"に計上されていた0x38がいずれも0に変わっています。
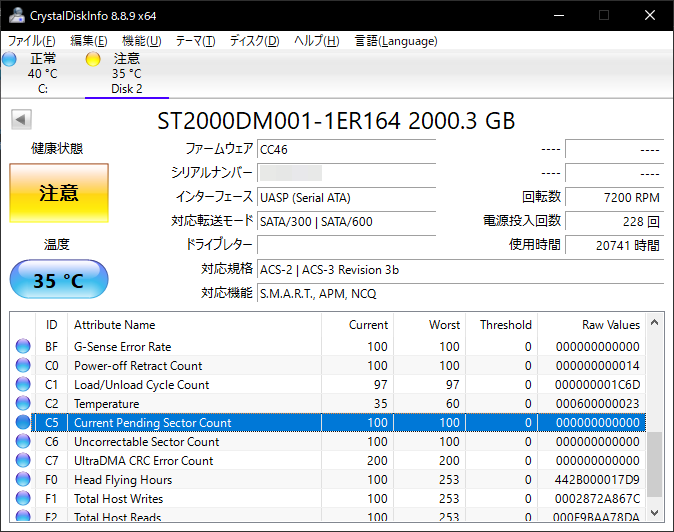
一方、"Reallocated Sectors Count"に0x38が計上されています。

つまり、SeaToolsによる「修復」では、"Current Pending Sector Count", "Uncorrectable Sector Count"に計上されたセクタを、"Reallocated Sectors Count"に移す処理が行われるようです。※それが具体的に何を意味するのかはこの時点では不明確ですが、後述。
Linuxで再確認
自動マウントが試みられますが、失敗します。syslogより抜粋。
kernel: [ 1844.343211] usb 2-4: new SuperSpeed Gen 1 USB device number 3 using xhci_hcd kernel: [ 1844.364833] usb 2-4: New USB device found, idVendor=0bc2, idProduct=3322, bcdDevice= 1.00 kernel: [ 1844.364844] usb 2-4: New USB device strings: Mfr=2, Product=3, SerialNumber=1 kernel: [ 1844.364851] usb 2-4: Product: Expansion Desk kernel: [ 1844.364857] usb 2-4: Manufacturer: Seagate kernel: [ 1844.364862] usb 2-4: SerialNumber: **************** kernel: [ 1844.376005] scsi host3: uas kernel: [ 1844.376567] scsi 3:0:0:0: Direct-Access Seagate Expansion Desk 4C01 PQ: 0 ANSI: 6 kernel: [ 1844.377141] sd 3:0:0:0: Attached scsi generic sg0 type 0 kernel: [ 1844.377248] sd 3:0:0:0: [sda] Spinning up disk... kernel: [ 1845.402986] ........ready kernel: [ 1852.571972] sd 3:0:0:0: [sda] 3907029167 512-byte logical blocks: (2.00 TB/1.82 TiB) kernel: [ 1852.571980] sd 3:0:0:0: [sda] 2048-byte physical blocks kernel: [ 1852.581264] sd 3:0:0:0: [sda] Write Protect is off kernel: [ 1852.581275] sd 3:0:0:0: [sda] Mode Sense: 4f 00 00 00 kernel: [ 1852.581513] sd 3:0:0:0: [sda] Write cache: enabled, read cache: enabled, doesn't support DPO or FUA kernel: [ 1852.581787] sd 3:0:0:0: [sda] Optimal transfer size 33553920 bytes not a multiple of physical block size (2048 bytes) kernel: [ 1852.646698] sda: AHDI sda1 sda2 kernel: [ 1852.649299] sd 3:0:0:0: [sda] Attached SCSI disk udisksd[762]: NTFS signature is missing. udisksd[762]: Failed to mount '/dev/sda1': Invalid argument udisksd[762]: The device '/dev/sda1' doesn't seem to have a valid NTFS. udisksd[762]: Maybe the wrong device is used? Or the whole disk instead of a udisksd[762]: partition (e.g. /dev/sda, not /dev/sda1)? Or the other way around? udisksd[762]: NTFS signature is missing. udisksd[762]: Failed to mount '/dev/sda2': Invalid argument udisksd[762]: The device '/dev/sda2' doesn't seem to have a valid NTFS. udisksd[762]: Maybe the wrong device is used? Or the whole disk instead of a udisksd[762]: partition (e.g. /dev/sda, not /dev/sda1)? Or the other way around? udisksd[762]: Failed to setup systemd-based mount point cleanup: Process reported exit code 5: Failed to start clean-mount-point@media-user-Seagate\x202TB1.service: Unit media-user-Seagate\x202TB1.mount not found. udisksd[762]: Failed to setup systemd-based mount point cleanup: Process reported exit code 5: Failed to start clean-mount-point@media-user-Seagate\x202TB.service: Unit media-user-Seagate\x202TB.mount not found. udisksd[762]: Mounted /dev/sda2 at /media/user/Seagate 2TB1 on behalf of uid 1000 udisksd[762]: Mounted /dev/sda1 at /media/user/Seagate 2TB on behalf of uid 1000 udisksd[762]: Cleaning up mount point /media/user/Seagate 2TB1 (device 8:2 is not mounted) udisksd[762]: Cleaning up mount point /media/user/Seagate 2TB (device 8:1 is not mounted)
SeaToolsで修復する前に出力されていたエラーは消えていますが、相変わらずパーティションのマウントに失敗しています。
fdiskで当該デバイス(/dev/sda)を確認してみると、以下のような状態となっています。
Command (m for help): p Disk /dev/sda: 1.8 TiB, 2000398933504 bytes, 3907029167 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: dos Disk identifier: 0x******** Device Boot Start End Sectors Size Id Type /dev/sda1 6579571 1924427647 1917848077 914.5G 70 DiskSecure Multi-Boot /dev/sda2 1953251627 3771827541 1818575915 867.2G 43 unknown /dev/sda3 225735265 225735274 10 5K 72 unknown /dev/sda4 2642411520 2642463409 51890 25.3M 0 Empty Partition 1 does not start on physical sector boundary. Partition 2 does not start on physical sector boundary. Partition 3 does not start on physical sector boundary. Partition table entries are not in disk order.
NTFSではなく、DiskSecure Multi-Bootやunknownとしてパーティションタイプが認識されています。
また、sda1パーティション内のセクタとsda3パーティションのセクタが重複していることになっています。同様にsda2内にsda4も重複しています。
これらのことからパーティションテーブルが壊れていると判断できます。こんな状態ではLinuxでもWindowsでもマウントできないのも納得です。
前述の通りデータは既に他のHDDに退避済みなので、このHDDはext4でフォーマットして再使用を試みることにします。
フォーマット…
fdiskで既存パーティションを全て削除し、GPTで新規パーティションを1つだけ作成します。
その後、特に何も考えずにext4でフォーマットしました。
$ sudo mkfs.ext4 /dev/sda1 mke2fs 1.44.1 (24-Mar-2018) Creating filesystem with 488378385 4k blocks and 122101760 inodes Filesystem UUID: cad555f3-bd20-4af6-8dbb-1c1ba83e6db5 Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848 Allocating group tables: done Writing inode tables: done Creating journal (262144 blocks): done Writing superblocks and filesystem accounting information: done
空の管理テーブル書くだけなのでサクッと終わります。
…が、不良領域が現れたHDDですので、これだけでは信頼性に疑問を感じます。
改めて、不良領域の存在をチェックしてからファイルシステムを生成するため、mkfsに-cオプションを指定して再実行します。
$ sudo mkfs.ext4 -c /dev/sda1 mke2fs 1.44.1 (24-Mar-2018) /dev/sda1 contains a ext4 file system last mounted on Sun Mar 28 05:47:20 2021 Proceed anyway? (y,N) y Creating filesystem with 488378385 4k blocks and 122101760 inodes Filesystem UUID: b315b3cb-3694-4cd8-9a1d-eb50a984a5ce Superblock backups stored on blocks: 32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968, 102400000, 214990848 Checking for bad blocks (read-only test): done Allocating group tables: done Writing inode tables: done Creating journal (262144 blocks): done Writing superblocks and filesystem accounting information: done
このHDDは約2TBの容量ですが、約3.5時間かけて特に警告などが表示されることも無く正常に終了しました。
正常終了?
…あれ?
確実に不良領域が存在するのに、何も警告されずに正常終了していいんだっけ?
というわけで冒頭の話になります。スキップセクタって誰が管理してるの?
ファイルシステムが管理しているのなら、ここで何も警告も異常も発生しないのはまずいのです。このままでは不良領域への読み書きがいつか発生し、再度データを失うことになってしまいます。
そうではなく、HDDのファームウェアが管理しているのならホスト(PC)側で異常を検出しないのは正常な挙動でしょう。
つまり、ホストはLBAを指定してHDD内のデータにアクセスしますが、HDDのファームウェアがPBAへのマッピング時にスキップセクタに該当するPBAを除外しているなら、ホスト側でエラーを検出しないのは正常な挙動と考えられます。
調べてみると、mkfsには-lオプションでbad block(不良領域)のリストを指定できることが判ります。すなわち、ファイルシステム側でスキップセクタを管理する機能が存在することになります。
ですが、不良領域が確実に存在するHDDに対して-cオプションで不良領域のチェックを行ったのに正常終了しているのです。ただし、-cオプションではreadのみをテストし、writeはテストされません。writeもテストすればエラーとして検出されるのではないかと考えました。
但しmkfs単独ではwriteのチェックはできないため、badblocksコマンドを用いて予め全領域のR/Wをテストします。badblocksの-oオプションで生成したbad blockリストをmkfsの-lオプションの入力ファイルとすることができます。
writeのテストを指定するには、badblocksに-wオプションを与えます。この時、デフォルトでは0xAA,0x55,0xFF,0x00のパターンがWriteされReadされます。つまり、既存データは上書きされて破壊されますので不用意に実行しないよう注意が必要です。
$ sudo badblocks -svw -o ./badblocks.list /dev/sda1 Checking for bad blocks in read-write mode From block 0 to 1953513542 Testing with pattern 0xaa: done Reading and comparing: done Testing with pattern 0x55: done Reading and comparing: done Testing with pattern 0xff: done Reading and comparing: done Testing with pattern 0x00: done Reading and comparing: done Pass completed, 0 bad blocks found. (0/0/0 errors)
結果的には、書き込みを伴うbadblocksによるチェックでも、不良領域は検出されませんでした。
なお、私は誤解していたのですが、0xAA,0x55,0xFF,0x00というbyte列を繰り返して先頭~最終セクタに書き込むのかと思いきや、全領域に0xAAをwrite/read、全領域に0x55をwrite/read、同様に0xFF,0x00についても全領域にwrite/readという挙動をします。すなわち、4パターン*領域サイズ分のDISKアクセスが発生しますので、検査対象HDDの容量に比例して長時間かかります。今回は2TBのHDDですが、余裕で丸一日以上かかりました。
ところで、0xFFや0x00はともかく、0xAAや0x55という値に何か意味あるのかと考えてみると、0xAA=0b10101010、0x55=0b01010101ですので、隣接するビットでread/writeエラーが発生しないことを検証する意図があるように思えます。
蛇足ながら、-wオプションを指定すると、デフォルトでは正常に記録が行えた領域には結果的に0x00が書き込まれた状態で終了することになります。これはPCやHDDの廃棄時にデータを完全消去するのにも使えそうです。実行後のHDDの様子をちょっと覗いてみましょう。
fdiskでsda1の情報を確認すると、以下の通りでした。
Disk /dev/sda1: 1.8 TiB, 2000397868032 bytes, 3907027086 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes
セクタ数3907027086なので、先頭セクタ(0)~最終セクタ(3907027086-1)であることとが特定できます。論理セクタサイズが512bytesであることも判りますので、実際に先頭セクタと最終セクタのデータを読み出してみます。
# dump first sector $ sudo dd if=/dev/sda1 bs=512 ibs=512 count=1 of=./sda1_head.bin 1+0 records in 1+0 records out 512 bytes copied, 0.000792227 s, 646 kB/s $ hd ./sda1_head.bin 00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00000200 # dump last sector $ sudo dd if=/dev/sda1 bs=512 ibs=512 count=1 skip=$((3907027086-1)) of=./sda1_tail.bin 1+0 records in 1+0 records out 512 bytes copied, 0.000830048 s, 617 kB/s $ hd ./sda1_tail.bin 00000000 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................| * 00000200
綺麗に0x00で埋め尽くされていることが判ります。
閑話休題。
…ここで、気付きます。ここまでにbadblocksで検査したのは「全領域」といいつつ、HDD(デバイス)の全領域ではなくパーティションの全領域であることを。
つまり、/dev/sda1の全領域をチェックしただけであり、/dev/sdaの全領域ではありません。
当然ながらデバイスsda全体の方がパーティションsda1よりセクタ数が多いので、sda1パーティション指定ではbadblocksの検査漏れセクタが存在します。
パーティション外の領域はパーティションテーブルそのものなど、HDD内の基本的な整合性を維持するために重要なメタデータが格納されるわけですから、そこをチェックしない訳にはいきません。
かと言って、再び丸一日以上かけてbadblocksをデバイス全体に再実行する気もありません。未検査の領域だけを追加で検査したいです。
改めてfdiskでsda1ではなくsdaの情報を確認すると、以下の通りでした。
Disk /dev/sda: 1.8 TiB, 2000398933504 bytes, 3907029167 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 4096 bytes I/O size (minimum/optimal): 4096 bytes / 4096 bytes Disklabel type: gpt Disk identifier: ********-****-****-****-************ Device Start End Sectors Size Type /dev/sda1 2048 3907029133 3907027086 1.8T Linux filesystem
sdaのセクタ数とsda1の開始・終了セクタ番号が判りましたので、sda1より前に位置する領域と、後に位置する領域だけを追加で検査します。
badblocksのブロックサイズ(-bオプション)に論理セクタサイズと同じ512を指定、開始ブロックを0、終了ブロックを2048の前(2047)に指定して、sda1より前に存在する全領域を検査します。※これに伴いパーティションテーブルが破壊されますので、元々正常なDISKでもマウントできなくなります。
$ sudo badblocks -svw -o ./badblocks_pre.list -b 512 /dev/sda 2047 0 Checking for bad blocks in read-write mode From block 0 to 2047 Testing with pattern 0xaa: done Reading and comparing: done Testing with pattern 0x55: done Reading and comparing: done Testing with pattern 0xff: done Reading and comparing: done Testing with pattern 0x00: done Reading and comparing: done Pass completed, 0 bad blocks found. (0/0/0 errors)
同様に開始ブロックを3907029133の次(3907029134)、終了ブロックを最終ブロックすなわち総ブロック数-1(3907029166)に指定して、sda1より後に存在する全領域を検査します。
$ sudo badblocks -svw -o ./badblocks_post.list -b 512 /dev/sda 3907029166 3907029134 Checking for bad blocks in read-write mode From block 3907029134 to 3907029166 Testing with pattern 0xaa: done Reading and comparing: done Testing with pattern 0x55: done Reading and comparing: done Testing with pattern 0xff: done Reading and comparing: done Testing with pattern 0x00: done Reading and comparing: done Pass completed, 0 bad blocks found. (0/0/0 errors)
これで、sda1パーティション前後の領域も含めてHDD全体のR/Wに問題無いことが確認できました。
このHDDの再使用に向けては、パーティションテーブルを破壊したため改めてfdiskでパーティション作成、mkfs.ext4でフォーマットを実施しました。
ところで、先述の通りext4はその機能の一部としてbad blockを管理できます。dumpe2fsコマンドに-bオプションを指定すればファイルシステムがbad blockであると認知しているブロックを表示することができます。
$ sudo dumpe2fs -b /dev/sda1 dumpe2fs 1.44.1 (24-Mar-2018)
結果、badblockは何も表示されませんでした。つまりこれまでの一連の流れでext4及び関連ツール群が何もエラーや警告表示をしてこなかったように、ファイルシステムとしてはこのHDDの不良領域の存在を認識していないことになります。
まとめ
これらのことから以下のことが言えるでしょう。
- スキップセクタの管理はHDD自体(のファームウェア) *2でもファイルシステムでも行える
- 今回の場合、スキップセクタを管理しているのはHDDのファームウェア
- Seagate製HDDの場合*3製造元のツールを使用して、ファームウェアにスキップセクタを認識させ当該PBAがLBAにマッピングされないようにすることができる
- この場合、ユーザが利用可能な総セクタ数(総容量)は変化しなかった
- スキップセクタのPBAに変わり、予め工場出荷時に確保されている予約済み領域のPBAがLBAに割り当てられたと考えられる
- 予約済み領域の残量を知る手段は無い*4
- ファイルシステムでスキップセクタを管理することもできる
以上。